概ね以下を参考に。
- 日本一わかりやすいLoRA学習!sd-scripts導入から学習実行まで解説!東北ずん子LoRAを作ってみよう!【Stable Diffusion】 - YouTube
- LoRAを一緒に作ろう!効率的なLoRA学習や、学習の設定を見ていこう【stable diffusion】 - YouTube
目次:
前提(環境準備)
A1111(Stable Diffusion web UI)、WD14-Taggerは導入済みとして進める。
WD14-Taggerの導入で発生するエラーについては以下を参照されたし。
interferobserver.hatenadiary.com
日本語Readmeを参考にkohya-ss/sd-scriptsの環境を導入
Powershellの実行権限で怒られるので、Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process -Forceで変更。
git clone https://github.com/kohya-ss/sd-scripts.git cd sd-scripts python -m venv venv Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process -Force .\vevn\Scripts\activate pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url https://download.pytorch.org/whl/cu118 pip install --upgrade -r requirements.txt pip install xformers==0.0.20 accelerate config
accelerate configを入力すると色々聞かれるけど、項目ごとに回答。
カーソルキーを使うとやり直しになるらしいので、数字キーで回答。
素材準備
素材集め
Google画像検索とかで画像を収集。
ここは割と手作業というか、根性で頑張った。
RPAとか使えば自動化できそうだけど、一旦は根性でやってみた。
画像ファイルのリネーム
連番にする必要があるらしいので、Pythonでスクリプトを作って連番振るようにした。
from os import rename, path from glob import glob from pathlib import Path inputpath = 'D:\Program\stable-diffusion-webui\materials\input' # 画像ファイルのみ抽出 types = ('jpg', 'png', 'webp', 'gif') files = [] for t in types: files += glob(path.join(inputpath, "*."+t)) # ファイル数の桁数を取得 digits_num = len(str(len(files))) for idx, file in enumerate(files): p_file = Path(file) # 連番にリネーム rename_to = path.join(inputpath, ("{:0"+str(digits_num)+"d}{}").format(idx, p_file.suffix)) rename(file, rename_to)
タグ付け
集めた素材を適当なフォルダーにまとめて入れる。
冒頭上げた動画をお手本に、WD14-Taggerでタグを付ける。
https://youtu.be/N1tXVR9lplM?si=qfmc6eLlRj0KNFRi&t=753
動画に対応するファイル名のテキストファイル(キャプションファイル)が生成されるはず。
キャプションファイルの編集
学習させたい要素をキャプションから取り除く必要がある。
タグファイルを1個ずつ開いてチェックして削除するのは手作業ではしんどいので、まとめて一括で削除する。
そのために、以下のような工程で編集する。
- どんなタグがいくつあるかをリスト化・集計する
- タグを特徴/服装/状態/背景/その他の5つに分類する
- 分類を参考にして除外リストを作成する
- 各キャプションファイルから除外リストのタグを取り除く
どんなタグがいくつあるかをリスト化・集計する
from os import path from glob import glob inputpath = 'D:\Program\stable-diffusion-webui\materials\input' outputpath = 'tags_count.txt' # txtのみ抽出 files = glob(path.join(inputpath, "*.txt")) # 各タグの出現回数を辞書型変数に格納していく tag_count = dict() for file in files: with open(file) as f: s = f.read() tags = s.split(',') for tag in tags: tag = tag.strip() if tag in tag_count.keys(): tag_count[tag] += 1 else: tag_count[tag] = 1 print("tags count: " + str(len(tag_count.keys()))) with open(outputpath, 'w', encoding='UTF-8') as f: # 出現回数の降順でソートして、タグとその出現回数を出力 for tag, count in sorted(tag_count.items(), key=lambda x:x[1], reverse=True): s = ("{}, {}\n".format(tag, count)) f.writelines(s)
タグを特徴/服装/状態/背景/その他の5つに分類する
これはChatGPTにお願いした。
こんな感じ。
次の英単語郡は、あるキャラクターのイラストに対して付けられたタグとその出現頻度です。それぞれの単語を以下の3通りに分類してください。また、各英単語とその日本語訳を付けてください。
1:特徴) キャラクターの身体的な特徴についての単語
2:服装) キャラクターの服装についての単語
3:状態) キャラクターの状態、ポーズ、表情、感情、行動についての単語
4:背景) キャラクターのいる場所、イラストの背景、構図についての単語
5:その他) 上の1から4に分類できない単語
出力の形態は以下のようにして、各英単語について1行としてください。
{英単語}, {出現頻度}, {分類}, {日本語訳}例えば、入力が
ahoge, 294
の場合は、出力は以下のようになります。
ahoge, 294, 1:特徴, アホ毛今回の対象の英単語郡は以下です。
animal ears, 439
1girl, 428
red hair, 418
solo, 386
ChatGPT 3.5でもまあ十分に機能した。
回答はこんな感じ。
animal ears, 439, 1:特徴, 動物の耳
1girl, 428, 3:状態, 1人の少女
red hair, 418, 1:特徴, 赤い髪
solo, 386, 3:状態, 単独
ただ、性的な表現に関連するタグを投げるとコンテンツフィルターに引っかかるという問題がある。
一度に40タグづつくらいの分量でChatGPTへ投げてはテキストにコピペ、をせっせと繰り返す。
これもOpenAIのAPIを使って自動化する余地はある。
分類を参考にして除外リストを作成する
これはもう手作業。分類と日本語訳があるからやりやすくはある。
各キャプションファイルから除外リストのタグを取り除く
Pythonスクリプトで、前工程で作った除外リストを参考にして、各キャプションファイルから除外して別フォルダーに除外後のキャプションファイルを再作成する。
同じフォルダーに画像ファイルがある場合はついでにそれもコピー。(まとめて使えるように)
from os import path from shutil import copy from glob import glob from pathlib import Path inputpath = 'D:\Program\stable-diffusion-webui\materials\input' exclusion_list_path = "exclusion_list.txt" outputpath = "D:\Program\stable-diffusion-webui\materials\image_tags(excluded)" # txtのみ抽出 tagfiles = glob(path.join(inputpath, "*.txt")) # 除外リストの1列目(単語)のみを抽出してset型変数に格納 with open(exclusion_list_path, 'r', encoding='UTF-8') as f: exclusion_tags = set([l.split(',')[0] for l in f.readlines()]) # 各タグファイルごとに除外リストの単語を除外して、除外後のタグをファイルに保存 for ifile in tagfiles: p_file = Path(ifile) # タグファイルを読み込んで除外した上でリスト変数に格納 with open(ifile, 'r') as f: tags = f.read().split(',') tags = [t.strip() for t in tags] tags = [t for t in tags if t not in exclusion_tags] # タグファイルと同名ファイルで除外済みリストを書き込み ofile = path.join(outputpath, p_file.name) with open(ofile, 'w') as f: f.write(', '.join(tags)) # 画像ファイルのみ抽出して出力フォルダーにコピー types = ('jpg', 'png', 'webp', 'gif') files = [] for t in types: files += glob(path.join(inputpath, "*."+t)) for file in files: copy(file, outputpath)
Kohya sd-scriptsの利用
Kohya sd-scriptsの準備
フォルダ作成
適当な場所に学習用フォルダを作り、その中に以下の3つのフォルダーを適当な名前で作る
・素材用
・正則画像用
・出力用
datasetconfig.tomlの準備
空のファイルdatasetconfig.tomlを作成し、テキストエディタで開き、以下のように書き込み。
[general] [[datasets]] [[datasets.subsets]] image_dir = 'D:\Program\Kohya\sd-scripts\TrainingData\materials' caption_extension = '.txt' num_repeats = 1
なお、image_dir = D:\Program\Kohya\sd-scripts\TrainingData\materials'の箇所は上で作成した素材用フォルダーのパスを代入するように記入する。
ファイルエンコードはUTF-8じゃないとだめらしい。
次に、再び空のファイルを作り、commandline.txtとして、以下のように記入。
accelerate launch --num_cpu_threads_per_process 1 train_network.py ^ --pretrained_model_name_or_path=**学習させたいモデルのパス ex. D:\Program\stable-diffusion-webui\models\hogehoge.safetensors** ^ --output_dir=**上で作ったouputフォルダーのパス ex.D:\TrainingData\outputs** ^ --output_name=**出力するLoRAファイルのファイル名(拡張子は勝手に付けられるので不要)** ^ --dataset_config=**上で作ったdatasetconfig.tomlのパス ex. D:\TrainingData\datasetconfig.toml** ^ --train_batch_size=1 ^ --max_train_epochs=1 ^ --resolution=512,512 ^ --optimizer_type=AdamW8bit ^ --learning_rate=1e-4 ^ --network_dim=128 ^ --network_alpha=64 ^ --enable_bucket ^ --bucket_no_upscale ^ --lr_scheduler=cosine_with_restarts ^ --lr_scheduler_num_cycles=4 ^ --lr_warmup_steps=500 ^ --keep_tokens=1 ^ --shuffle_caption ^ --caption_dropout_rate=0.05 ^ --save_model_as=safetensors ^ --clip_skip=2 ^ --seed=42 ^ --color_aug ^ --xformers ^ --mixed_precision=fp16 ^ --network_module=networks.lora ^ --persistent_data_loader_workers
適宜自分の環境に合わせて2〜5行目のフォルダパス、ファイルパスを変更するように。
max_train_epochsは画像の枚数によっては10とか20とかにしてもいいかもしれないけど、とりあえず初回実行はすぐ終わるようにして、出力まで正しく動くことを確認した方がいいと思う。
最初からうまくいくことはなかなかなくて、設定ミスとか、なんか出力先が違ってたとか色々起こるもんなので。
うまくいったら処理時間みながら徐々に増やしていけば良い。
Kohyasd-scriptsの実行
sd-scriptsをクローンしたフォルダに移動し、コマンドプロンプトを開いて以下を実行。
.\kohya\Scripts\activate
続いて、先ほどcommandline.txtに保存しておいたaccelerate launch以降のコードをコピペして実行。
実行エラー「ImportError: No bitsandbytes / bitsandbytesがインストールされていないようです」
File "D:\Program\Kohya\sd-scripts\train_network.py", line 1012, in <module>
trainer.train(args)
File "D:\Program\Kohya\sd-scripts\train_network.py", line 342, in train
optimizer_name, optimizer_args, optimizer = train_util.get_optimizer(args, trainable_params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Program\Kohya\sd-scripts\library\train_util.py", line 3446, in get_optimizer
raise ImportError("No bitsandbytes / bitsandbytesがインストールされていないようです")
ImportError: No bitsandbytes / bitsandbytesがインストールされていないようです
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code(前後省略)
bitsandbytesってなにそれ?ってことでググってみると
bitsandbytes - としあきdiffusion Wiki*
GitHubページ:https://github.com/TimDettmers/bitsandbytes
略語は「bnb」
sd-scriptsで学習する際、8bitオプティマイザーを使うときに必須なライブラリ。
bits and bytesの名の通り、fp32から品質を落とさずに軽量な8bit行列に変換するのに使う。
改めて確認したら、sd-scripts側のREADMEにも書いてあるな。
sd-scripts/README-ja.md at main · kohya-ss/sd-scripts · GitHub
オプション:bitsandbytes(8bit optimizer)を使う
bitsandbytesはオプションになりました。Linuxでは通常通りpipでインストールできます(0.41.1または以降のバージョンを推奨)。Windowsでは0.35.0または0.41.1を推奨します。
bitsandbytes 0.35.0: 安定しているとみられるバージョンです。AdamW8bitは使用できますが、他のいくつかの8bit optimizer、学習時のfull_bf16オプションは使用できません。
bitsandbytes 0.41.1: Lion8bit、PagedAdamW8bit、PagedLion8bitをサポートします。full_bf16が使用できます。
注:bitsandbytes 0.35.0から0.41.0までのバージョンには問題があるようです。 TimDettmers/bitsandbytes#659以下の手順に従い、bitsandbytesをインストールしてください。
ってことなんで、おとなしく従う。
0.41.0を入れてみる。
python -m pip install bitsandbytes==0.41.1 --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
実行エラー「No module named 'triton'」
No module named 'triton' - としあきdiffusion Wiki*
直訳すると「triton」モジュールがなかったという意味。
エラーコードとして、発生する場合がある。Windowsの場合はtritonに対応していないため、この表示が出て、かつコード実行に問題がなければ無視しても良い。
【参考】このエラーはたとえば、sd-scripts dev版でかつ一定以上のVer.のPyTorch(?)を使っていると登場する。
うーん・・・?とりあえず、無視して良いらしいので無視!
実行中
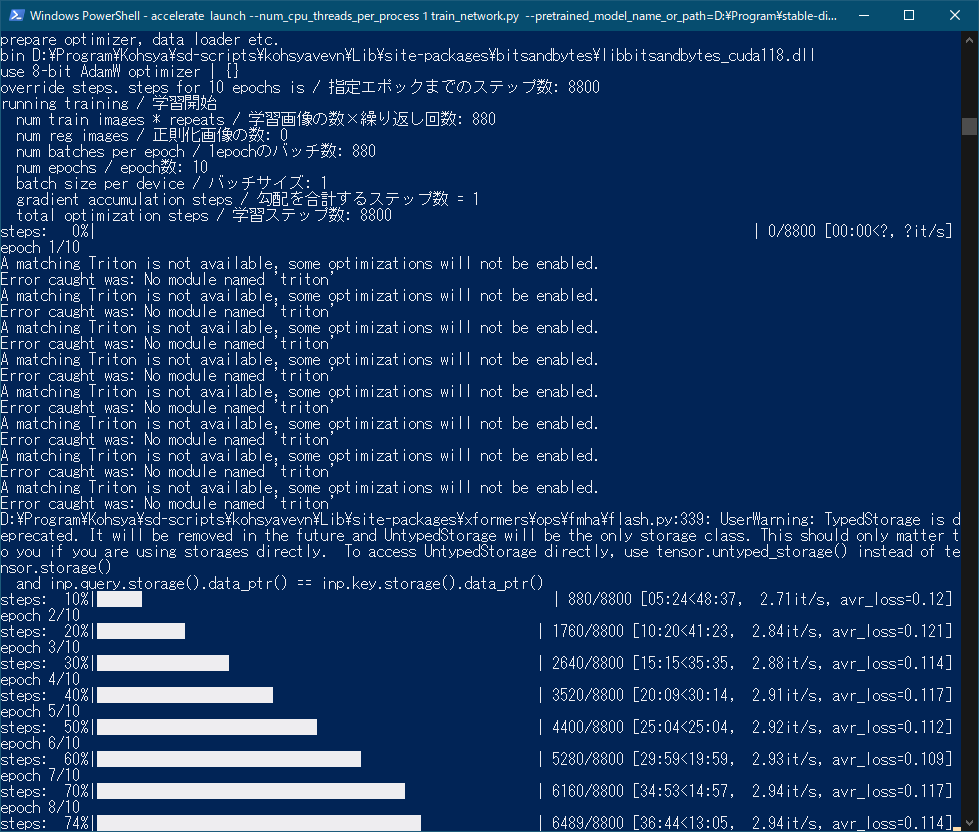
RAMとVRAMをごりっと使う。

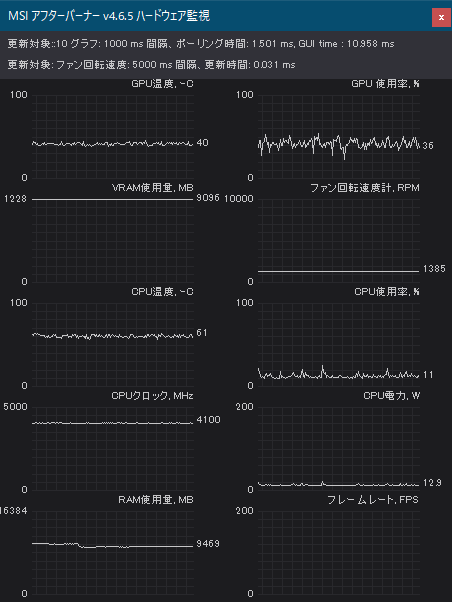
やり始めて気づいたのおバカなんだけど、Google Chromeだのメモリを食うアプリケーションは閉じてから実行開始したほうがよかったな。
始まってからあとから閉じても使ってくれない。
今後やりたいこと
今回はとりあえずKohya sd-scriptsを動かしてLoRAを作ってみる、という目的で、とりあえずは達成できた。
今後は以下のことに挑戦したい。
- LoRA作成時のパラメータを調整したい。とりあえずの今の設定だと、たぶんまだPCのボトルネックに達していない。
- 2パターンの衣装に対応できていない。多分タグづけをもっと頑張ればできそう。けど、全部目でチェックするのは大変なので、なんか工夫して楽にやりたい。
wd14-taggerの新高性能モデルmoat-tagger-v2を使ってみよう!|でんでん
-
- 今回は画像については拾ったものを無加工で使ってたけど、他のキャラクターが含まれていたり、服装が違うものは分けて学習したりタグを調整するともっと精度はあがるかもしれない。
- VAEを使ってみる